Внутренняя платформа автоматизации
Зачем она нам
Почти каждый заказ на автоматизацию раскладывается на одни и те же кирпичи: куда-то сходить за данными, что-то над ними сделать, результат положить в базу, отправить уведомление и показать оператору результат. Менять под каждый проект оркестратор, писать свой UI, выдумывать способ доставки задач до воркеров — долго, дорого и скучно.
Мы собрали платформу, на которой новый проект — это не новая система, а несколько новых скриптов и пара таблиц в базе.
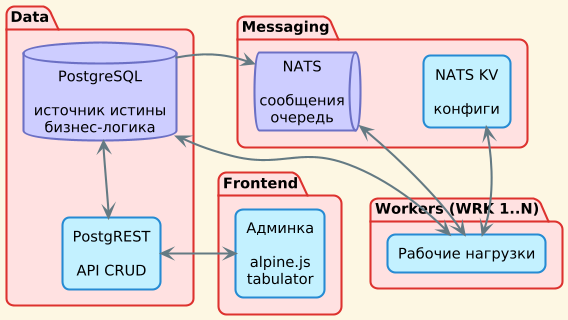
Как устроено
Три независимых слоя, каждый делает одно дело:
- Данные. PostgreSQL — единственный источник истины. Задачи, состояние, результаты, бизнес-логика — всё в обычных таблицах. Поверх — PostgREST, который автоматически раздаёт CRUD-API из схемы БД.
- Сообщения. NATS переносит задачи от ядра к воркерам и обратно. NATS KV хранит конфиги, которые воркер читает при старте.
- Исполнение. Воркеры — обычные Python-процессы. Разворачиваются на любых площадках (наши серверы, инфраструктура заказчика, арендованные GPU) и подключаются к ядру через overlay-сеть на базе NetBird (ZTNA).
Админка на Alpine.js + Tabulator смотрит в PostgREST. Оператор видит очереди, результаты, может перезапустить задачу, аналитик — выгрузить срез в excel.
Что это даёт
Расширяемость: новый тип нагрузки — новый скрипт
Каждая задача в БД помечена типом — PARSE_SITE, BROWSER_FLOW,
AI_CLASSIFY, и так далее. Воркер, получив задачу, запускает одноимённый
Python-скрипт. Добавить новый тип — значит добавить строку
в справочник и положить рядом скрипт. Без пересборки
ядра, без правок в UI, без миграций очередей.
Нагрузки бывают разные и хорошо уживаются в одной системе: короткие вызовы на сотни миллисекунд, браузерные сценарии на несколько минут, GPU-инференс, многочасовые выгрузки. Воркеры поднимаются под конкретный профиль нагрузки: CPU-шные — на дешёвых VPS, GPU-шные — на машинах с видеокартами.
Масштабируемость: десятки воркеров на разных площадках
Воркеры не знают друг о друге и не знают, где живёт ядро. Они забирают задачи из NATS и кладут результат обратно. Добавить мощности — запустить ещё один контейнер, он сам придёт в overlay-сеть и подпишется на очередь.
География не имеет значения: воркер в дата-центре, воркер на ноутбуке аналитика, воркер на арендованной GPU — для ядра они неотличимы. NetBird даёт шифрованный L3 поверх любого интернета, без проброса портов и белых IP.
Прозрачность: бизнес-логика в SQL, а не в чёрном ящике
Состояние workflow не спрятано внутри оркестратора — оно лежит
в PostgreSQL. Аналитик открывает админку и видит
всё: что выполнилось, что упало и почему, сколько заняло, какие параметры
пришли на вход. Разбор инцидента — это SELECT, а не поход
в специализированный UI с закрытым форматом логов.
Триггеры и функции PostgreSQL делают часть бизнес-логики прямо в БД — так она остаётся транзакционной и проверяемой.
Отсутствие vendor lock-in
Ни одного проприетарного компонента:
- PostgreSQL, NATS, NetBird, Python, nginx — всё open source
- Воркер — это обычный Python-скрипт, не привязанный к SDK платформы
- Данные — в стандартной реляционной БД, забираются обычным
pg_dump - Платформа разворачивается на инфраструктуре заказчика целиком, без обращений к нашим облакам
Скорость разработки
Типовая новая интеграция — от постановки до продакшена за дни, не недели. Ядро уже решает 80% работы: очереди, ретраи, хранение результатов, API, админка. Команда пишет только ту логику, которая уникальна для проекта: как распарсить этот конкретный сайт, как кликать по этой конкретной форме, как классифицировать эти конкретные тексты.
Кому это
Заказчикам, у которых есть повторяющиеся процессы, жалко времени людей и не хочется платить за SaaS-платформу, в которой однажды закончится бесплатный тариф, а миграция окажется дороже переписывания с нуля. Типичные сценарии, которые мы на ней уже решаем:
- Парсинг сайтов и API — от разовых сборов до непрерывного мониторинга
- Браузерные автоматизации рутинных операций в веб-интерфейсах, у которых нет публичного API
- ИИ-инференс: классификация, извлечение сущностей, суммаризация — на собственных GPU-воркерах, без отправки данных наружу
В цифрах
| Показатель | Значение |
|---|---|
| Воркеров в проде | десятки, на разных площадках |
| Задач в сутки | тысячи |
| Типы нагрузок | от миллисекунд до нескольких часов, CPU и GPU |
Технологии
- Данные: PostgreSQL, PostgREST
- Сообщения: NATS, NATS KV
- Исполнение: Python, Docker
- Сеть: NetBird (ZTNA, overlay-сеть между ядром и воркерами)
- Админка: Alpine.js, Tabulator